Valor32k-AVQA v2.0: Open-Ended Audio-Visual Question Answering Dataset and Benchmark

May 30, 2025
Abstract
Despite growing interest in Audio-Visual Question Answering (AVQA), existing datasets often suffer from limited diversity, rigid formats, and insufficient integration of audio and visual modalities. To address these limitations, we introduce Valor32k-AVQA v2.0, a large-scale dataset containing 28,863 real-world videos and over 225,000 QA pairs, designed to support diverse and realistic multimodal understanding. The dataset features both open-ended and multiple-choice questions, each annotated with the required modality (visual, audio, or audio-visual) and question category (description, action, count, temporal, location, or relative position). All annotations—including questions, answers, and metadata—are generated through a fully automated prompting pipeline using GPT-4o, with human validation performed on a representative sample to ensure quality. We benchmark two state-of-the-art models, VideoLLaMA2 and Crab, and observe that adding audio consistently improves performance when models are fine-tuned, without degrading visual reasoning capabilities. These findings highlight that the audio signals in our dataset are not only well integrated, but also informative and complementary, establishing Valor32k-AVQA v2.0 as a valuable resource for developing and evaluating robust audio-visual question answering systems.
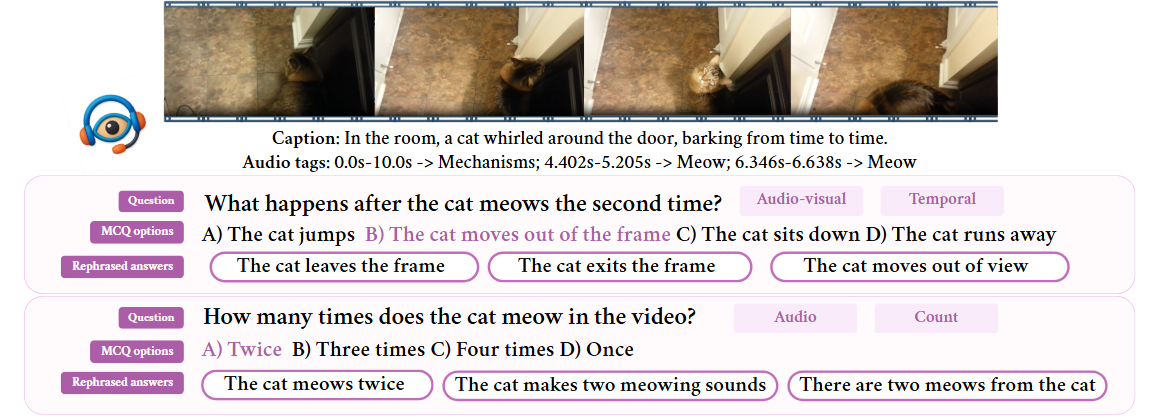
Valor32k-AVQA v2.0 Dataset
Dataset Description
Valor32k-AVQA v2.0 is a large-scale, open-ended audio-visual question answering dataset containing 28,863 real-world videos and over 225,000 QA pairs. Each question is tagged by required modality (Visual, Audio, or Audio-Visual) and categorized into one of six types: Description, Action, Count, Temporal, Location, or Relative Position. All annotations are automatically generated using a GPT-4o pipeline, with a subset manually validated to ensure quality. The dataset supports both open-ended and multiple-choice formats and is split into standard train, validation, and test sets. With diverse content, rich annotations, and a balanced modality distribution, Valor32k-AVQA v2.0 offers a strong benchmark for multimodal reasoning.
Samples from the Dataset
In the room, a cat whirled around the door, barking from time to time.
How many times does the cat meow in the video?
- The cat meows twice
- The cat makes two meowing sounds
- There are two meows from the cat
Three times
Twice (✓)
Four times
Once
What happens after the cat meows the second time?
- The cat leaves the frame
- The cat exits the frame
- The cat moves out of view
The cat jumps
The cat moves out of the frame (✓)
The cat sits down
The cat runs away
With the sound of the horn, two men happily take drinks on the road while talking.
What is the man in the gray shirt holding in his right hand?
- A beverage
- A cup
- A drink
A book
A bag
A drink (✓)
A phone
What are the two men doing while walking on the road?
- Conversing and drinking
- Chatting and drinking
- Talking and sipping
Talking and drinking (✓)
Reading and walking
Running and shouting
Listening to music
As the water rang, a man in black was fishing by the river and then talking.
What sound accompanies the man's action in the video?
- Talking
- Conversing
- Speaking
Birds chirping
Wind blowing
Car honking
Speech (✓)
Where is the man located in the video?
- Next to the river
- Beside the river
- At the riverbank
In a forest
In a city park
By the river (✓)
On a mountain
In the ranch, a man holds a horse and speaks.
What happens after the man starts leading the horse?
- The horse makes a snorting sound
- A snort is heard from the horse
- The horse emits a snort
The horse stops moving
The horse neighs
The horse snorts (✓)
The horse starts running
How many horses are visible in the video?
- There are two horses
- Two horses are seen
- The video shows two horses
Two (✓)
One
Four
Three
Outside, a crowd of men around a star speaks this in English, making noisy people.
What is the man in the white shirt doing while a shout is heard?
- Gazing downward
- Facing down
- Head tilted down
Looking down (✓)
Talking
Walking
Waving
Where is the man in the white shirt located in the video?
- Center of the crowd
- Crowd's middle
- Crowd's center
In the middle of the crowd (✓)
Behind the crowd
In front of the crowd
At the edge of the crowd
In the dark, a lighted light shone on a plane's propeller, which was turning and buzzing.
What is the position of the light relative to the propeller in the video?
- The light is situated above the propeller
- The light is located above the propeller
- The light is positioned above the propeller
To the left of the propeller
Below the propeller
Above the propeller (✓)
To the right of the propeller
What background sound is heard in the video?
- Engine humming
- Engine droning
- Engine noise
Engine buzzing (✓)
People talking
Water flowing
Birds chirping
Prompt Examples
Prompt with Strong Audio Tags
Video ID: -uGHAvfqs2I
You are provided with 8 sequential video frames, along with
their time spans for audio and video.
Additionally, a brief caption describes the video content and audio details. Use
this information to create questions that require watching the video to be
answerable, avoiding general knowledge questions.
Modality Definitions:
Visual: Answer is fully derived from the video frames alone.
Audio: Answer relies only on audio information.
Audio-Visual: Both audio and visual information are essential for a
100% accurate answer.
Question Categories:
Relative Position (Visual): Ask about the position of one object
relative to another.
Description: Ask 3 questions. Visual: about
visual details, excluding movement. Audio: about audio-only details
(example background sounds). Audio-Visual: Combine visual and audio
details (example "Does <item> produce sound?")
Action: Ask 2 questions. Visual: about
movements in the video. Audio-Visual: Link sounds to movements (example
"What sound accompanies a movement?")
Temporal: Ask 3 questions. Visual: Compare
events happening before, after, or during specific times visually.
Audio: Compare events happening before, after, or during specific times
from audio. Audio-Visual: Combine events from both modalities (example
"What do you see before hearing <event>?").
Count: Ask 3 questions. Visual: Count items
visible in the video. Audio: Count the frequency of specific sounds.
Audio-Visual: Link counts across modalities (example "How many
<items> do you both see and hear?").
Location: Visual: Ask about the locations of
objects or scenes in the video.
Guidelines for Question Generation: Only generate questions
when the video or caption provides clear and specific information. Do not invent
details
Avoid using the term “frames” in questions. Refer to "the
video" instead
Ensure questions require specific observation of the video and are not general
knowledge
Answer Format: 1. Multiple-choice format:
Provide 4 options, with only one correct answer
Ensure all options are of similar length
Answer Variations:
Include the correct answer along with three rephrased versions of the
answer
Additional Fields for Each Question:
Quality Rating: - Obvious: The answer is easily
inferred from the provided information. - Guess: The answer likely
exists but is not obvious.
Inference Check: Indicate whether the question itself contains
part of the answer or if the answer can’t be inferred directly.
Modality: Visual, Audio, or Audio-Visual.
Category: from the listed categories (example Relative
Position, Description).
Source Tags: Indicate the sources used to create the question
as tags: Frames, Caption, Audio
Frame timestamps: 1st->0.0s, 2st->0.8s, 3st->1.0s,
4st->3.0s, 5st->4.0s, 6st->7.0s, 7st->8.0s, 8st->9.6s
Audio tags: 0.0s-10.0s -> Mechanisms; 4.402s-5.205s
-> Meow; 6.346s-6.638s -> Meow
Caption: In the room, a cat whirled around the door, barking
from time to time.
Return format one line json:
{"questions":[{"question":"string","options":["string","string","string","string"],"correct_answer_idx":int,"rephrased_answers":["string","string","string"],"quality_rating":"string
(obvious | guess)","modality":"string (visual | audio |
audio-visual)","category":"string (relative-position | description | action |
temporal | count |
location)","source_tags":["frames","caption","audio"]}]}
0.00s

0.80s

1.00s

3.00s

4.00s

7.00s

8.00s

9.60s

Prompt without Strong Audio Tags
Video ID: Sv9fcuRfk2o
You are provided with 10 sequential video frames, The video
includes audio, which I can describe for you as tags.
Additionally, a brief caption describes the video content and audio details.
Use this information to create questions that require watching the video to
be answerable, avoiding general knowledge questions.
Modality Definitions:
Visual: Answer is fully derived from the video frames alone.
Audio: Answer relies only on audio information.
Audio-Visual: Both audio and visual information are essential for a
100% accurate answer.
Question Categories:
Relative Position (Visual): Ask about the position of one object
relative to another.
Description: Ask 2 questions. Visual:
about visual details, excluding movement. Audio: about audio-only
details (example background sounds)
Action: Ask 2 questions. Visual: about
movements in the video. Audio-Visual: Link sounds to movements
(example "What sound accompanies a movement?")
Temporal: Ask 1 question which event happened
before the other (visual)
Count: Ask 1 question about how many specific
items seen (visual)
Location: Visual: Ask about the locations
of objects or scenes in the video.
Guidelines for Question Generation: Only generate questions
when the video or caption provides clear and specific information. Do not
invent details
Avoid using the term “frames” in questions. Refer to "the
video" instead
Ensure questions require specific observation of the video and are not
general knowledge
Answer Format: 1. Multiple-choice format:
Provide 4 options, with only one correct answer
Ensure all options are of similar length
Answer Variations:
Include the correct answer along with three rephrased versions of the
answer
Additional Fields for Each Question:
Quality Rating: - Obvious: The answer is easily
inferred from the provided information. - Guess: The answer likely
exists but is not obvious.
Inference Check: Indicate whether the question itself
contains part of the answer or if the answer can’t be inferred
directly.
Modality: Visual, Audio, or Audio-Visual.
Category: from the listed categories (example Relative
Position, Description).
Source Tags: Indicate the sources used to create the
question as tags: Frames, Caption, Audio
Frame timestamps: 1st->0.0s, 2st->1.0s, 3st->2.0s,
4st->2.9s, 5st->3.7s, 6st->5.0s, 7st->6.0s, 8st->6.4s,
9st->8.0s, 10st->9.2s
Audio tags: Car alarm
Caption: With the sound of the horn, two men happily take
drinks on the road while talking.
Return format one line json:
{"questions":[{"question":"string","options":["string","string","string","string"],"correct_answer_idx":int,"rephrased_answers":["string","string","string"],"quality_rating":"string
(obvious | guess)","modality":"string (visual | audio |
audio-visual)","category":"string (relative-position | description | action
| temporal | count |
location)","source_tags":["frames","caption","audio"]}]}
0.00s

1.00s

2.00s

2.90s

3.70s

5.00s

6.00s

6.40s

8.00s

9.20s

Dataset Statistics
Unique Videos
28,863
Total Questions
225,487
Avg Questions/Video
7.81
Unique Words
22,639
Category Breakdown
Modality Breakdown
Question Length Statistics
Average
9.95
Minimum
2
Maximum
31
Interactive Visualizations
Experiments
| Model | Setup | Overall Metrics | CIDEr by Modality | CIDEr by Category | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BLEU-4 | METEOR | ROUGE-L | SPICE | BERT-F1 | Accuracy (%) | CIDEr | Audio | Visual | Audio-Visual | Description | Action | Count | Temporal | Location | Rel.-Position | ||||
|
VideoLLaMA2 w/o audio |
O–S | 0.0738 | 0.1312 | 0.2138 | 0.1244 | 0.2205 | 37.70 | 0.3665 | 0.1909 | 0.4617 | 0.2516 | 0.4467 | 0.2697 | 0.2095 | 0.2576 | 0.5280 | 0.8769 | ||
| FT | 0.1188 | 0.1425 | 0.3152 | 0.1434 | 0.2815 | 49.64 | 0.7463 | 0.4505 | 0.9096 | 0.5266 | 0.6808 | 0.5728 | 0.2775 | 0.7386 | 1.1141 | 2.1975 | |||
|
VideoLLaMA2 with audio |
O–S | 0.0439 | 0.1207 | 0.1729 | 0.0974 | 0.1690 | 39.75 | 0.2558 | 0.1734 | 0.2975 | 0.2169 | 0.3204 | 0.2123 | 0.1648 | 0.2333 | 0.2073 | 0.4050 | ||
| FT | 0.1254 | 0.1526 | 0.3368 | 0.1564 | 0.2977 | 53.86 | 0.8183 | 0.6134 | 0.9466 | 0.6175 | 0.7819 | 0.6670 | 0.2904 | 0.8122 | 1.2046 | 2.1923 | |||
|
Crab w/o audio |
FT | 0.0701 | 0.1231 | 0.2329 | 0.1287 | 0.2769 | 41.31 | 0.4259 | 0.2001 | 0.5348 | 0.3152 | 0.3216 | 0.3306 | 0.1352 | 0.4564 | 0.7658 | 1.5613 | ||
|
Crab with audio |
FT | 0.0710 | 0.1270 | 0.2392 | 0.1340 | 0.2837 | 44.37 | 0.4401 | 0.2454 | 0.5336 | 0.3518 | 0.3365 | 0.3507 | 0.1454 | 0.4665 | 0.7136 | 1.6741 | ||
|
VAST w/o audio |
FT | 0.0978 | 0.1263 | 0.2910 | 0.1281 | 0.1845 | 45.26 | 0.6448 | 0.3963 | 0.7696 | 0.4870 | 0.5984 | 0.5243 | 0.2330 | 0.6258 | 0.9372 | 1.7846 | ||
|
VAST with audio |
FT | 0.1007 | 0.1290 | 0.2975 | 0.1327 | 0.1901 | 46.93 | 0.6660 | 0.4644 | 0.7710 | 0.5225 | 0.6339 | 0.5461 | 0.2337 | 0.6464 | 0.9626 | 1.7843 | ||
|
Ola-7B w/o audio |
O–S | 0.0891 | 0.2064 | 0.3211 | 0.2032 | 0.2597 | 32.89 | 0.5002 | 0.3141 | 0.6496 | 0.2154 | 0.4756 | 0.2681 | 0.8820 | 0.1877 | 0.8161 | 0.9582 | ||
| FT | 0.1036 | 0.1260 | 0.2819 | 0.1202 | 0.1805 | 40.27 | 0.5953 | 0.3151 | 0.7664 | 0.3390 | 0.5504 | 0.4291 | 0.1908 | 0.5234 | 0.9759 | 1.9712 | |||
|
Ola-7B with audio |
O–S | 0.1164 | 0.2230 | 0.3389 | 0.2319 | 0.2981 | 39.22 | 0.6274 | 0.4734 | 0.7728 | 0.3338 | 0.6183 | 0.3835 | 1.0194 | 0.3137 | 0.9214 | 1.1509 | ||
| FT | 0.1064 | 0.1271 | 0.2883 | 0.1292 | 0.1762 | 45.21 | 0.6532 | 0.4392 | 0.7773 | 0.4662 | 0.6269 | 0.4949 | 0.2115 | 0.5844 | 0.9978 | 2.0202 | |||
Table 1: Selected evaluation metrics for several LMMs in zero-shot (O–S) and fine-tuning (FT) setups without and with audio input. *Extra models are under testing.
| Model | Setup | Accuracy by Modality (%) | Accuracy by Category (%) | Overall (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Audio | Visual | Audio-Visual | Description | Action | Count | Temporal | Location | Rel.-Position | ||||
|
VideoLLaMA2 w/o audio |
O–S | 45.94 | 56.75 | 55.66 | 62.39 | 58.59 | 36.12 | 53.74 | 63.38 | 45.38 | 54.46 | |
| FT | 63.09 | 65.77 | 69.53 | 71.17 | 70.55 | 52.74 | 66.03 | 70.56 | 58.40 | 66.06 | ||
|
VideoLLaMA2 with audio |
O–S | 57.12 | 57.05 | 64.28 | 68.88 | 66.95 | 36.66 | 56.86 | 62.77 | 43.14 | 58.58 | |
| FT | 67.52 | 64.95 | 71.41 | 73.33 | 74.12 | 55.35 | 62.63 | 68.79 | 52.23 | 66.80 | ||
|
Crab w/o audio |
FT | 28.05 | 29.41 | 30.64 | 27.69 | 31.48 | 24.82 | 33.44 | 31.54 | 28.06 | 29.42 | |
|
Crab with audio |
FT | 39.04 | 37.46 | 44.41 | 38.86 | 44.53 | 28.56 | 44.59 | 39.09 | 36.08 | 39.23 | |
|
VAST w/o audio |
FT | 73.04 | 65.98 | 75.56 | 78.03 | 78.78 | 59.50 | 61.69 | 68.39 | 46.53 | 69.34 | |
|
VAST with audio |
FT | 74.01 | 65.65 | 76.35 | 78.53 | 79.18 | 59.50 | 61.63 | 68.13 | 45.76 | 69.49 | |
|
Ola-7B w/o audio |
O–S | 55.67 | 66.18 | 61.81 | 69.38 | 65.11 | 48.14 | 63.19 | 73.09 | 58.32 | 63.26 | |
| FT | 62.26 | 68.20 | 67.70 | 73.70 | 70.76 | 51.28 | 66.46 | 74.25 | 58.63 | 66.97 | ||
|
Ola-7B with audio |
O–S | 69.70 | 67.82 | 72.37 | 78.58 | 74.24 | 52.49 | 66.10 | 73.04 | 58.55 | 69.13 | |
| FT | 72.97 | 70.36 | 77.03 | 80.90 | 79.08 | 53.55 | 70.29 | 75.57 | 62.94 | 72.26 | ||
Table 2: Multiple choice question (MCQ) accuracy by modality, category, and overall, for each model and setup.
References
- Cheng, Zesen; Leng, Sicong; Zhang, Hang; Xin, Yifei; Li, Xin; Chen, Guanzheng; Zhu, Yongxin; Zhang, Wenqi; Luo, Ziyang; Zhao, Deli; et al. 2024. VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs. arXiv preprint arXiv:2406.07476.
- Du, Henghui; Li, Guangyao; Zhou, Chang; Zhang, Chunjie; Zhao, Alan; Hu, Di. 2025. Crab: A Unified Audio-Visual Scene Understanding Model with Explicit Cooperation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 18804–18814.
- Chen, Sihan; Li, Handong; Wang, Qunbo; Zhao, Zijia; Sun, Mingzhen; Zhu, Xinxin; Liu, Jing. 2024. Vast: A Vision–Audio–Subtitle–Text Omni-Modality Foundation Model and Dataset. Advances in Neural Information Processing Systems, 36.
- Liu, Zuyan; Dong, Yuhao; Wang, Jiahui; Liu, Ziwei; Hu, Winston; Lu, Jiwen; Rao, Yongming. 2025. Ola: Pushing the Frontiers of Omni-Modal Language Model. arXiv preprint arXiv:2502.04328.
Download Dataset
- combined_dataset_train_flattened.json
- combined_dataset_val_flattened.json
- combined_dataset_test_flattened.json
- combined_dataset_train.json
- combined_dataset_val.json
- combined_dataset_test.json
- eval_segments.csv
- balanced_train_segments.csv
- unbalanced_train_segments.csv
- class_labels_indices.csv
- mid_to_display_name.tsv
- audioset_eval_strong.tsv
Note: The dataset is provided for research purposes only. Please refer to our license terms for usage conditions.
Dataset source: VALOR Repository
Dataset File Contents
Combined Dataset (Flattened) Files
The “flattened” JSON files each contain a list of individual question objects. Every object represents a single question generated for a particular 10-second video clip. Each entry includes:
- caption: The original video caption from Valor32K (e.g., “With the rumble, on a moving bus, a crowd spoke.”).
- video_id: Unique identifier for the source video segment (e.g., “x-2Abohj8VY”).
- question: The question generated by GPT-4o (or GPT-3.5 if generation failed).
- options: An array of four answer options (all similar length; only one is correct).
- correct_answer_idx: Index (0–3) indicating which option is correct.
- rephrased_answers: Three alternative phrasings of the correct answer.
- quality_rating: “obvious” if the answer can be directly inferred, or “guess” otherwise.
- modality: One of visual, audio, or audio-visual depending on which cues are needed to answer.
- category: Question category from relative-position, description, action, temporal, count, location.
- source_tags: Tags indicating information sources (e.g., “frames”, “caption”, “audio”).
- id: Unique identifier for each question entry in the flattened list.
- oid: Original ID linking back to the grouped (unflattened) entry for that video.
- model: Specifies “gpt4o” or “gpt3.5” indicating which model generated the question.
Combined Dataset (Unflattened) Files
The unflattened JSON files group multiple questions under each unique video ID. Each top‐level entry includes:
- video_id: Unique identifier for a 10-second video segment.
- caption: The original Valor32K caption for that segment.
- prompt: The text prompt used to generate the questions in this entry (shown only in unflattened form).
- questions: An array of question objects (similar structure to flattened entries, but grouped by video). Rare entries where GPT generates invalid modality or category are filtered out here.
- oid: Numerical ID for the video.
- model: Specifies “gpt4o” or “gpt3.5” indicating which model generated the question.
Example Entry (Flattened)
{
"caption": "With the rumble, on a moving bus, a crowd spoke.",
"video_id": "x-2Abohj8VY",
"question": "What color shirt is the person sitting in the front right wearing?",
"options": [
"Green",
"Blue",
"Red",
"Yellow"
],
"correct_answer_idx": 1,
"rephrased_answers": [
"The shirt is blue",
"The person is wearing a blue shirt",
"The color of the shirt is blue"
],
"quality_rating": "obvious",
"modality": "visual",
"category": "description",
"source_tags": [
"frames"
],
"id": 1,
"oid": 0,
"model": "gpt4o"
}
In this example:
- caption and video_id come from Valor32K’s original segmentation.
- question and options were generated by GPT-4o (or GPT-3.5 if generation failed).
- correct_answer_idx (0-based) points to “Blue” in the options array.
- rephrased_answers provides three paraphrases of “Blue.”
- quality_rating “obvious” indicates this question can be answered directly from the provided information.
- modality “visual” means only visual cues are needed to answer.
- category “description” indicates a question about a static detail (shirt color).
- source_tags “frames” shows that no audio cues were required here.
- id and oid help link back to unflattened groupings.
- model specifies which GPT version generated this question.
BibTeX
@inproceedings{riahi2025valor32k,
author = {Riahi, Ines and Radman, Abduljalil and Guo, Zixin and Hedjam, Rachid and Laaksonen, Jorma},
title = {Valor32k-AVQA v2.0: Open-Ended Audio-Visual Question Answering Dataset and Benchmark},
year = {2025},
isbn = {9798400720352},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3746027.3758261},
doi = {10.1145/3746027.3758261},
booktitle = {Proceedings of the 33rd ACM International Conference on Multimedia},
pages = {13097--13103},
numpages = {7},
keywords = {audio-visual question answering (avqa), avqa dataset, multimodal fine-tuning, multimodal understanding},
location = {Dublin, Ireland},
series = {MM '25}
}